Распознавание образов
Распознавание образов является необходимым условием во многих автоматических процессах. К примеру, автоматическому сварочному аппарату приходится «самостоятельно» отыскивать то место, на которое он должен приварить соответствующую деталь. Однако задача становится еще интереснее, когда от машины требуется распознавание сложных образов. Известный пример тому — считывающее устройство, способное декодировать и распознать рукописный текст. Ведущая роль в подобных процессах принадлежит опять-таки синергетическим эффектам. На первом этапе происходит разложение букв на отдельные элементы, так называемые элементарные характерные образы или примитивы (рис. 17.2).
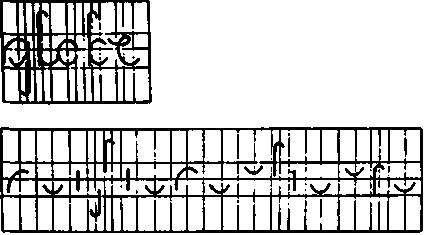
Рис. 17.2. Распознавание образа путем разложения его па отдельные элементы («примитивы»)
Элементы эти подбираются так, что они могут быть восприняты машиной, скажем, как прямые и дугообразные линии, расположенные определенным образом. Такие элементы могут быть «восприняты» фотоэлементами и затем «опознаны» с помощью сравнительно простых устройств. Каждому элементу в зависимости от места его расположения сопоставлено некоторое число (рис. 17.3).
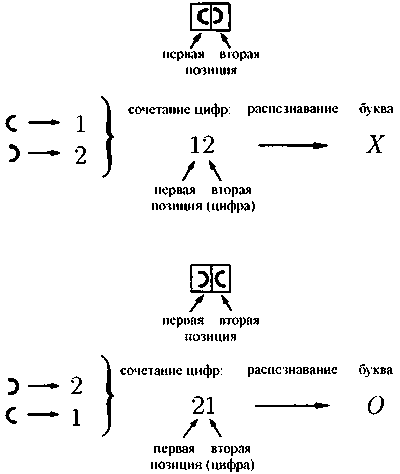
Рис. 17.3. Простой пример сопоставления примитивам чисел в зависимости от взаимного расположения примитивов
Аналогично тому, как замок с цифровым кодом открывается одной-единственной комбинацией цифр, каждая буква располагает своей собственной комбинацией цифр, соответствующих каждому из элементов этой буквы и определяющих именно эту букву. Машина проверяет наличие в имеющемся у нее перечне данной цифровой комбинации и опознает соответствующую букву как, например, букву «А». Трудности при использовании такого метода распознавания вызваны тем, что он заведомо не исключает возникновения ошибок: безупречная идентификация элементов букв — не допускающая смешения, допустим, вертикальной линии и открытого справа дугообразного элемента — попросту невозможна. Таким образом, мы возвращаемся к старой задаче об отыскании способов исправления ошибок. Такого рода явления уже встречались нам при рассмотрении лазера или движения жидкости. В каждой из упомянутых систем также вполне вероятно наличие нескольких элементов, изначально «шагающих не в ногу» с остальными. Допустим, несколько атомов в лазере испускают волны «неправильной» длины, или не все молекулы жидкости принимают участие в общем движении. Однако такие «отщепенцы» очень быстро оказываются, что называется, «прибраны к рукам» параметром порядка. Для считывающего устройства это означает, что в случае отсутствия в перечне какой-либо из обнаруженных комбинаций машина должна попытаться подобрать среди существующих наиболее близкую к ней. С этой целью используются некоторые чисто математические методы. Например, каждому числу ставится в соответствие определенная точка на координатной плоскости (рис. 17.4).
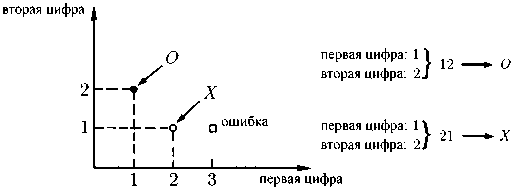
Рис. 17.4. Представление сопоставленных буквам чисел точками на координатной плоскости. В первом случае идентифицирована точка, соответствующая букве О, во втором — точка, соответствующая букве X. Комбинация же, состоящая из цифр «3» и «1», отсутствует в перечне заданных комбинаций, вследствие чего соответствующий результат распознавания считается ошибочным. Представленная система основывается всего на двух координатах; на практике же применяются многомерные системы координат
При обнаружении ошибки измеряется расстояние между каждой из заданных в перечне точек и точкой, соответствующей «сомнительному» числу. При этом, впрочем, возможна ситуация, требующая нарушения симметрии (рис. 17.5): проверяемая точка равноудалена от имеющихся в памяти машины «правильных» точек.
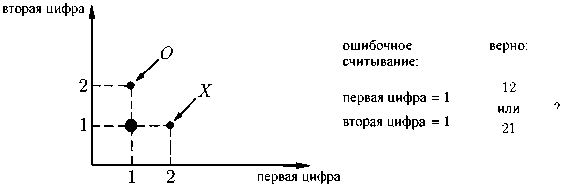
Рис. 17.5. Пример неуверенного распознавания. Машина определила обе цифры как единицы, но в ее перечне комбинаций отсутствует буква с таким цифровым соответствием: имеются лишь цифровые комбинации «12» и «21», соответствующие буквам О и X (см. рис. 17.4). Точка «11» находится на равном расстоянии как от той, так и от другой; следовательно, для принятия решения необходимо нарушение симметрии
В этом случае машина беспомощна: для идентификации ей недостает дополнительных критериев, в рамках которых она могла бы принять решение. Когда при распознавании рукописного слова или фразы машина оказывается не в состоянии решить, соответствует ли прочитанная ею буква, скажем, точке X или точке О, то, как показывает опыт, машина может принять решение на основании того, как распознанное слово или предложение выглядят целиком. Сопоставив полученную целостную картину с грамматическими нормами языка или просто проверив отдельные слова на предмет осмысленности, машина может наконец однозначно решить, каким же все-таки образом должна выглядеть сомнительная буква. Этот пример наглядно показывает, что при последовательном распознавании знаков принятие окончательного решения относительно содержания того или иного знака может оказаться весьма непростым делом.
Описанный метод является относительно жестким, ведь для верной идентификации считываемые машиной «палочки» и «крючочки» должны быть расположены по отношению друг к другу совершенно определенным образом. В случае с печатным текстом, в котором шрифт соответствует неким нормам, машинное чтение осуществимо без особых проблем; однако с рукописными текстами машина зачастую оказывается беспомощна. Для распознавания рукописных текстов разрабатываются другие методики: в их основе лежит то обстоятельство, что отдельные примитивы располагаются по отношению друг к другу определенным образом, аналогично тому, как слова в предложении занимают место, определенное им синтаксическими законами данного языка. На практике эта аналогия между грамматикой и системой взаимного расположения примитивов используется для создания инструкций, в соответствии с которыми машина будет действовать в процессе синтеза отдельных элементов в знаки (например в буквы алфавита). При этом машинному разуму приходится не один раз оказаться перед выбором, подобно человеку на развилке в лабиринте; путь же к желанному выходу и синтезу буквы из примитивов указывает анализ их взаимного расположения.
Более 800 000 книг и аудиокниг! 📚
Получи 2 месяца Литрес Подписки в подарок и наслаждайся неограниченным чтением
ПОЛУЧИТЬ ПОДАРОК